

Як працює War of Words — новий ШІ-інструмент для аналізу російської пропаганди
Як працює War of Words — новий ШІ-інструмент для аналізу російської пропаганди



Передісторія створення
Після початку повномасштабної війни команда засновників War of Words доєднувалася до різних волонтерських медіапроєктів із моніторингу й аналізу російської пропаганди та дезінформації. Цим займалися багато діячів із медійної сфери, проєкти приносили користь. Але чим більше ми заглиблювалися, тим більше розуміли, наскільки це масштабна пропагандистська машина, і що аби її якось приборкати, потрібна потужна системна робота, для якої ми не мали на той час інструменту.
Росія — ТБ-центрична країна: попри розповсюдженість інтернет-ресурсів, телебачення залишається джерелом інформації №1. Ми зрозуміли, що комплексно аналізувати інформаційний потік без нього немає сенсу. Примітно, що від початку повномасштабної війни на ворожому ТБ одразу різко зросла кількість пропагандистського політичного контенту. Наприклад, популярне токшоу «60 хвилин» почало тривати більш ніж дві години — звучить сюрреалістично, але факт. І навіть самі російські опитування, на репрезентативність яких не варто сильно покладатися, все ж визнають, що прихильність ТБ прямо корелюється з підтримкою війни: так, результати 2022 року від так званого «ВЦИОМ» говорять, що серед тих, хто дивиться телебачення щоденно, війну підтримують 75%, натомість серед тих, хто не дивиться щоденно, — 42%. І це досить ілюстративно.
Проблема полягала в тому, що з технологічної точки зору аналізувати телебачення складно. Вручну на обробку 10 годин програм можуть піти десятки годин. Тож ми почали думати, як створити якісний автоматичний інструмент, шукали різні технології. Ми прагнули глибоко підійти до аналітики й збирати не тільки контент від поточного часу, а й показати у ретроспективі, що російське ТБ багато років формувало ненависть до України й інших країн і як їхні пропагандистські наративи змінювалися з часом.
Також важливо було якісно перекладати контент англійською, зі збереженням стилістики мови ненависті, аби іноземні державні діячі, дипломати, журналісти та дослідники могли правильно розуміти всі нюанси того, що говорили в ефірі.
Як працює інструмент
Ми завантажили всі новинні й інформаційно-політичні телепрограми на ключових каналах з 2012 року, вони зберігаються у хмарному архіві, що розташований за межами України та Росії. Навіть якщо завтра росіяни видалять свої відео з усіх джерел — у нас цей контент залишиться з усіма метаданими. Наразі це понад 100 тис. годин відео та аудіо. Архів поповнюється та розшифровується щоденно.
Хмарні обчислення та розшифровка відео та аудіо архіву в тексти російською відбуваються за допомогою технології Microsoft Azure, а англійською їх перекладає Chat GPT-4.
Більшість LLM-моделей уже навчені компаніями та надають базову відповідь — цензурований текст без емоційного забарвлення. Тому ми використовуємо специфічні налаштування LLM-моделей зі складним набором промптів. Сюди зокрема належить функція контекстуального перекладу. Наприклад, якщо хтось на ТБ говорить слово «піндоси», у текстовому перекладі буде примітка, що це зневажлива назва пропагандистами американців. Це дуже важлива задача — передати саме емоційний контекст, а не тільки суху інформацію.
LLM-модель також дозволяє класифікувати контент за певними наративами, меседжами. Можна проводити статистичний аналіз висловів, скільки разів було згадано той чи той наратив, враховуючи непрямі висловлювання. Цікаво також відстежувати, наскільки синхронізовано відбувається поява нових слів і меседжів — зачасту вони з’являються одночасно година в годину на різних джерелах, як за єдиною вказівкою.
І остання складова — це сайт із відкритим сервісом для користувачів, де є можливість шукати за ключовими словами англійською та мовою оригіналу, а також фільтрувати результати за датою, типом медіа, джерелами, програмами, спікерами й іншими параметрами. Плюс є дашборди, що дозволяють відстежувати все це в динаміці. У розширеній версії для дослідників є додаткові можливості, як-от завантаження корпусів розпізнаних текстів однією кнопкою — для окремого аналізу.
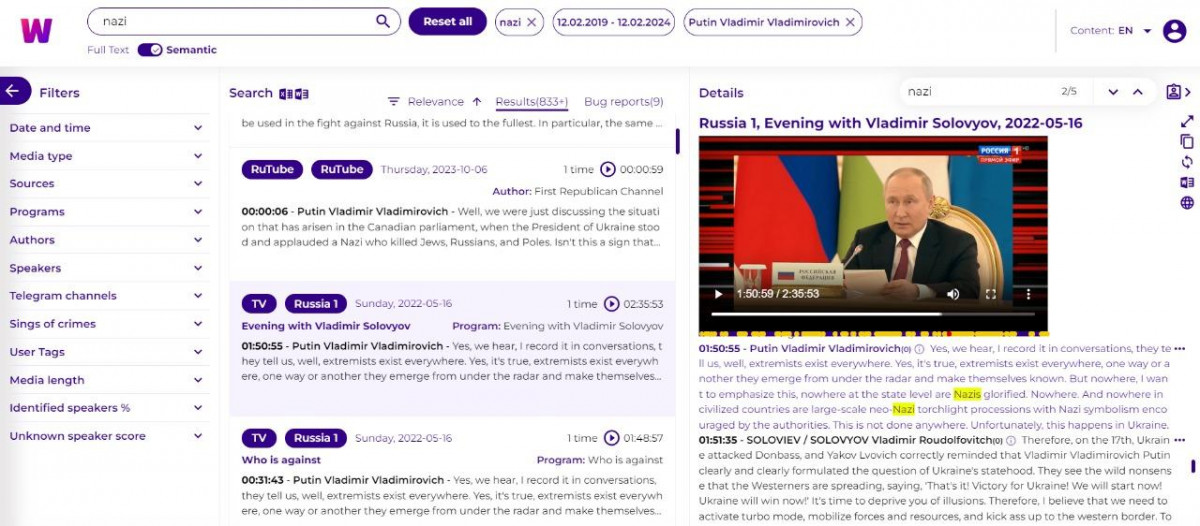
Приклад 1
Наприклад, ми хочемо дізнатися, що говорив Путін за останній рік на телебаченні про нацистів. Стартовий екран виглядає так:
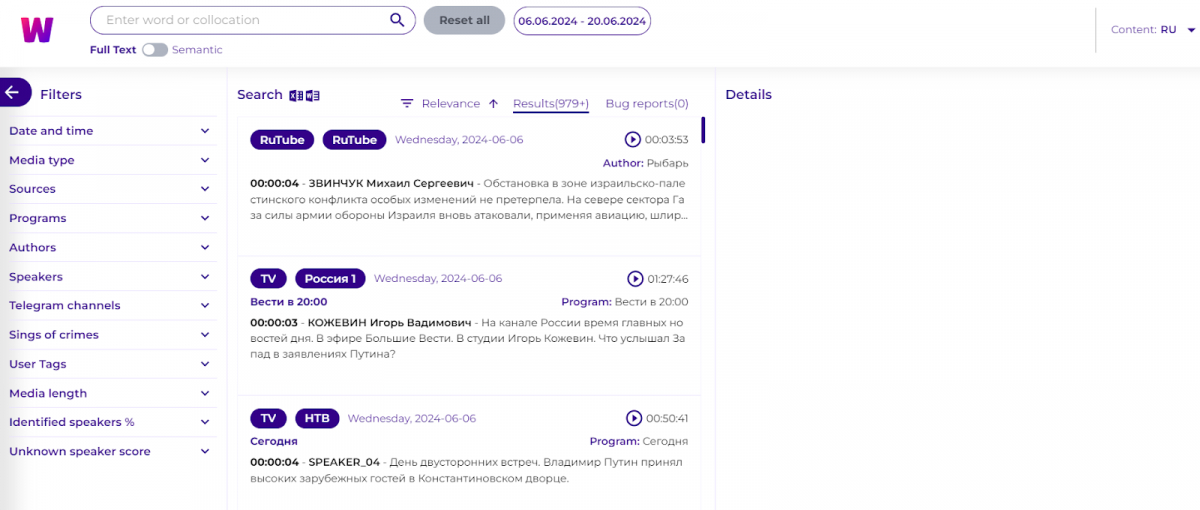
Формуємо запит:
- вводимо «нацист*» у поле пошуку, щоб отримати всі програми, де це слово використовувалось у різних граматичних формах та зворотах;
- обираємо дату 1Y (один рік) і тип медіа TV;
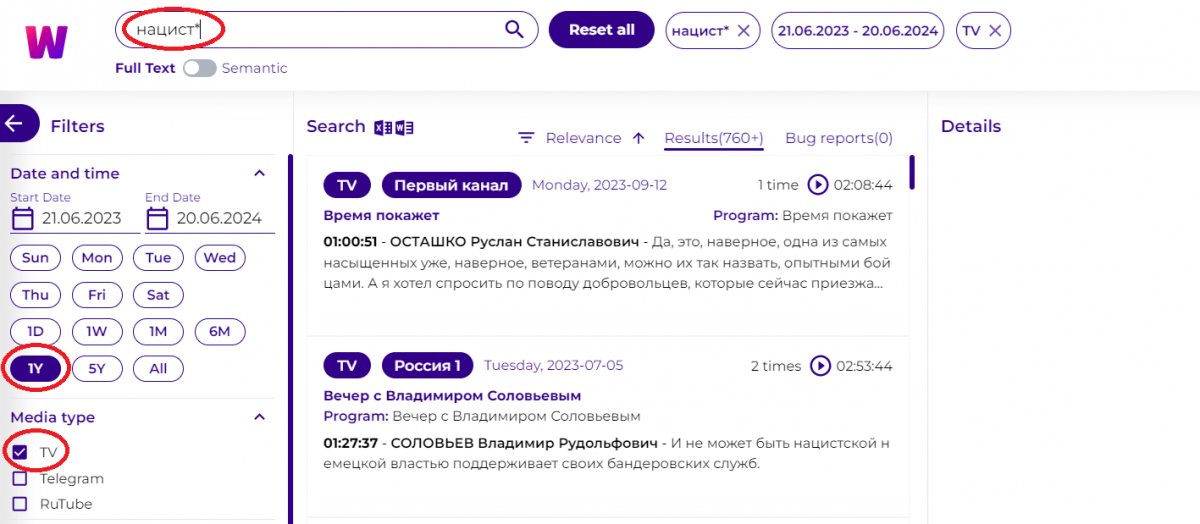
Нижче в полі вибору спікера вводимо прізвище Путіна російською мовою і вибираємо його.
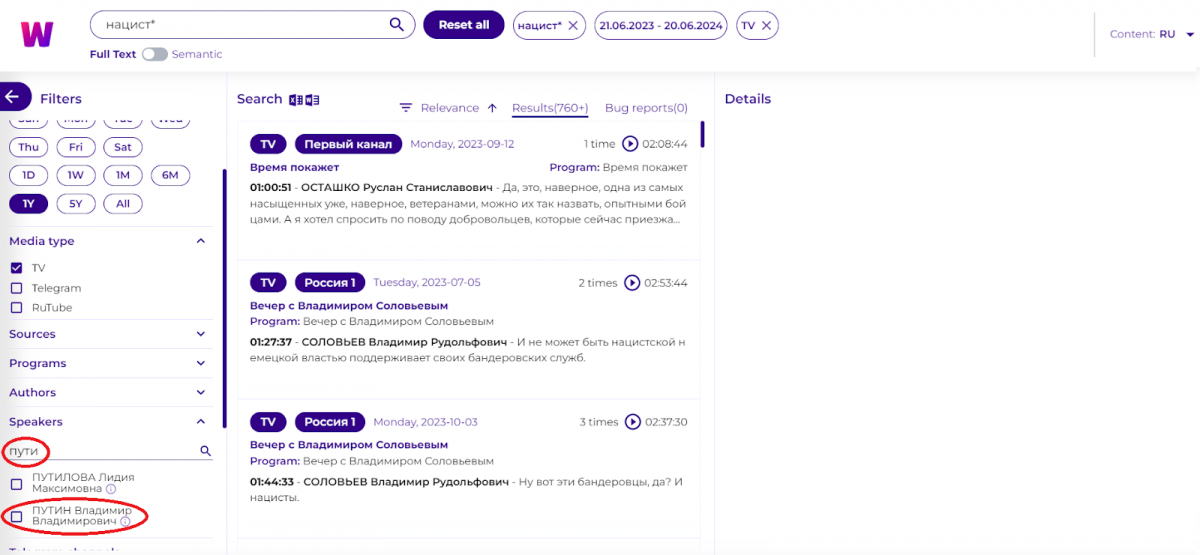
Також можемо відсортувати видачу, наприклад, за датою ефіру, так, щоб останні програми були нагорі:
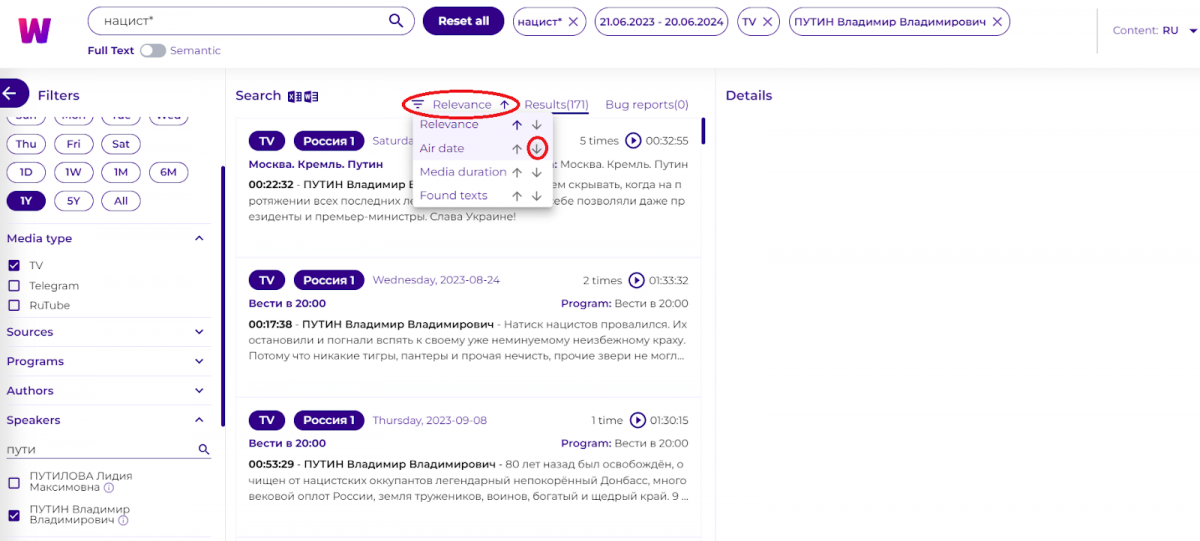
Клікаємо на першу програму, справа відкривається вікно з текстом і відео (його можна розкрити на весь екран, для цього треба натиснути виділену червоним овалом іконку з двома стрілочками з правого меню):
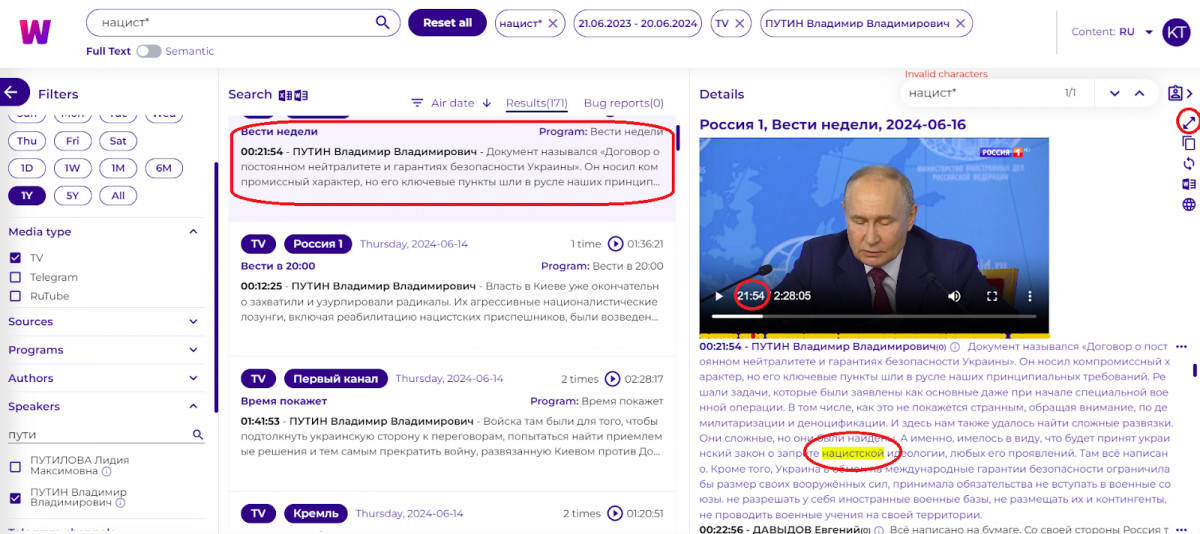
Відео і текст одразу перемотані на місце, де слово із запиту зустрічається вперше, слово виділене жовтою підсвіткою. Користувач може натиснути на програвання відео і насолоджуватися промовою воєнного злочинця Володимира Путіна.
Приклад 2
Можливо, ви побачили статтю з цікавим фрагментом і хочете знайти всю програму. Наприклад:
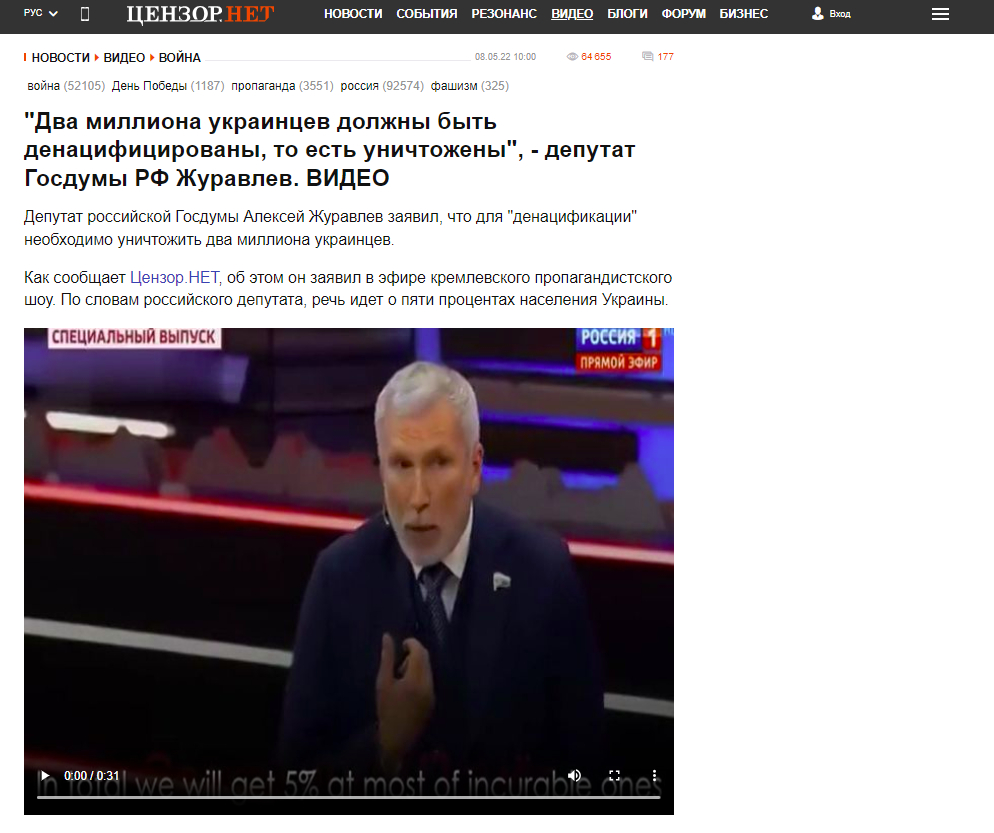
Бачимо, що матеріал вийшов 8 травня 2022-го, тож маємо обмеження за датою пошуку (скоріше за все, програма вийшла кілька днів тому, але про всяк випадок поставимо широкий діапазон, який потім можна звужувати, якщо буде випадати надто багато випусків зі схожими текстами). Також знаємо ім’я спікера — Олексій Журавльов — і знаємо, що сказано це було на каналі «Росія 1».
Розставляємо фільтри:
- Запит — «*миллиона украинцев должны быть денацифицированы». Зірочка на початку дає можливість не втрачати дані залежно від того, як система розшифрувала числа — цифрами чи літерами.
- Дата 01.01.2012 — 08.05.2022
- Канал: Росія 1
- Спікер: Олексій Журавльов
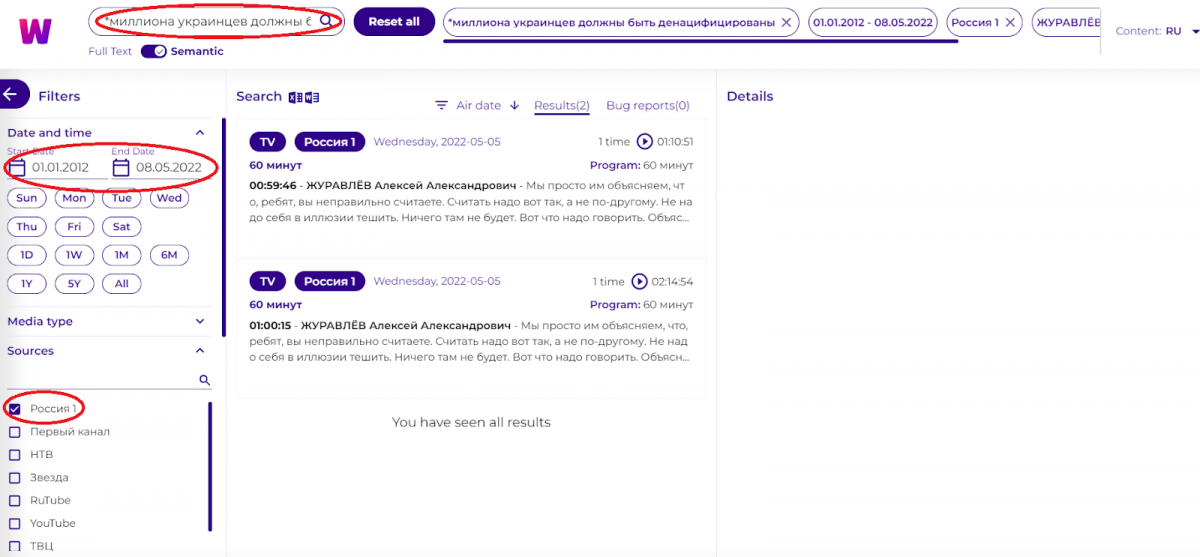
Цього разу пощастило, одразу знаходимо потрібний матеріал:

Це програма «60 минут» від 5 травня 2022. Бігунок уже встановлено на потрібному місці на відео і в тексті.
Висновок: виклики та майбутні складові платформи
У роботі інструменту War of Words є певні виклики. Наприклад, сайти російських телеканалів, де ми беремо всі відео, періодично змінюють посилання, тому потрібен час, аби ідентифікувати нове і повернутися до завантаження знову.
Також, як і в будь-якій системі, є невеликий відсоток неправильних розпізнавань голосів, адже спікери інколи кричать, інколи шепочуть, інколи говорять одночасно, і ШІ це збиває, як і людей, власне. Аби максимізувати точність, ми вручну маркували в системі близько 700 основних спікерів.
Нові моделі та технології розвиваються дуже швидко, і це теж певний виклик — платформу треба постійно оновлювати. Зараз ми шукаємо фінансування, аби зробити деякі технологічні покращення, зокрема інтегрувати chat GPT так, щоб можна було вводити менш чіткі запити й отримувати більш комплексні відповіді.
Також хочемо створити більш глибоку систему фільтрування контенту за контекстом — щоб працювали кнопки «геноцид», «викрадення дітей», «стаття 119» тощо, видаючи в пошуку відповідні випадки. Таке збагачення даних було б дуже доречним для інформаційного підкріплення російських злочинів і ще більше зекономило б час держорганам у підготовці кримінальних справ. До речі, з держорганами ми вже працюємо, передаємо їм матеріали для таких справ або перевіряємо їхні гіпотези щодо пропагандистських тез Росії.
Крім цього, ми працюємо над додатковим маркуванням текстів на ознаки агресії, порушення міжнародного чи українського законодавства.
Перебуваючи в тилу, кожен із нас має певну відповідальність у тому, аби сприяти протистоянню ворогу. Ми вирішили зробити інструмент для допомоги слідству й адвокації України в боротьбі з російським злом у світі, а також надати іншим країнам можливість відстежувати та передбачати російську агресію у свій бік.
Ілюстрація на головній: Getty Images







